研究内容
2017 年 5 月の改正個人情報保護法施行により,本人の同意がなくとも第三者提供ができる「匿名加工情報」の利用が始まった.しかしながら,匿名加工情報の再識別リスクはそれほど自明ではなく,標準的な評価手法は定まっていない.例えば,匿名加工に関するリスクには特定,識別,属性推定などの多様性があり,対象とするデータの性質や攻撃者の仮定に応じて大きく変動するために,標準的な加工方法を決めることが出来ない.そこで, 本研究では多くの研究者により加工技術の有用性と安全性を集積し,優れたアルゴリズムを探求するオープン型の評価コンテストを企画し,信頼できる匿名加工技術の開発を試みる.匿名加工に関する課題に対して,1. オープンデータベースの 開発,2. 有用性指標の設計,3. 攻撃者の知識モデルと安全性指標の設計,4. 匿名加工アルゴリズムの開発,5. 位置情報の属性推定とテンソル分解による学習手法の研究,6. コンテストの評価環境 の構築,のそれぞれを研究目的とする.
学術的背景, 研究課題の核心をなす学術的「問い」
ビッグデータの持つ価値を最大限に利用しようとするビジネス活動が急速に進展している.Google, Amazon, Facebook, Apple(GAFA) の活動に代表されるターゲット広告では,GAFA が収集した個人データをビジネスに最大限に利用して巨額の利益を得ている.一方,個人データは発生源である データ主体自身のプライバシー保護を確保することが要請される.プライバシー保護はヨーロッパ では理念,人権として確立しているため,インターネット時代のおけるプライバシー保護のための 法整備として,2017 年 EU では GDPR(General Data Protection Regulation) が成立し,2018 年に 施行される.日本では 2016 年個人情報保護法が改正され,世界では類を見ない独自の概念として匿名加工情報が導入された.匿名加工情報は,個人データをデータ主体が容易に識別できないように処理することによって,ビジネス利用においてデータ主体の同意を必要とすることなく,自由な利 活用ができるようにしたデータである.匿名加工情報がビジネスにおいて機能することは個人データの有効利用に資するところが大きい.
個人データの有用性保持とプライバシー保護は相反する目的なので,両者のバランスが重要である.匿名加工情報は,完璧な識別不可能は無理であるにしても,データ主体の識別ができないほど十分な匿名化処理が必要とされるよう に加工された個人データのデータベースである.しかしながら,匿名加工情報が再識別されるリスクを正しく評価することはそれほど自明ではない.
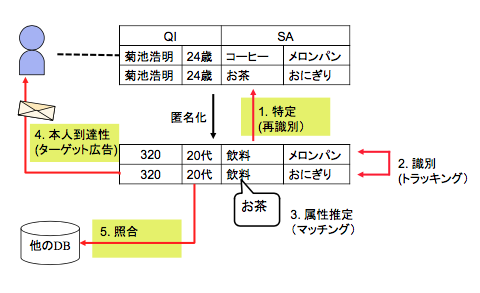
この困難さを理解するために,図 1 の例を考えよう.この匿名加工データから元のデータを 復元し,特定の個人を識別(特定)することを,特定, 複数のレコードが同一の顧客のものであることを突き止めることを識別, 一般化された概念かのインパクトもまちまちである(問題 1 リスクの多様性).
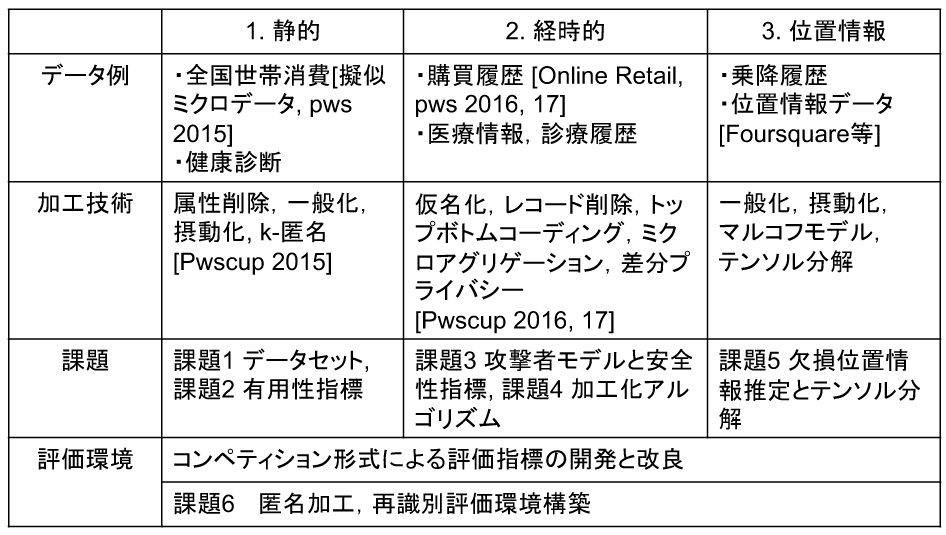
個人データは,表 1 に示される 3 つの類型に 分類して匿名加工を検討する.例えば,1 においては,同一の静的属性値を持つレコードが k 個以上になることを保証する k-匿名性を満たす加工方式が有効だが,時刻によって値が動的に 変化する 2 の履歴に適用することは出来ない.このように,多様な対象データの全てに適用できる完全な加工方法は存在しない.匿名加工されたデータを識別する攻撃者のモデルについて多くの研究がなされているが,どのような背景知識や能力を仮定するべきかという点では結論が出ていない(問題 2 万能な匿名加工方法はない).
完璧な識別不能性を実現するのは困難であるとしたら,どこまで加工したら広く認められる安全な加工と言えるだろうか?
目的および学術的独自性と創造性
そこで,本研究では,多様なデータの問題点に対して,表 1 に示した 3 つの類型について,共通のデータセットを指定して,データに依存する固有の問題を明確にするアプローチをとる. 静的なデータと時系列を含む動的な経時データを明確に分けることにより,表 1 に示すように,そ れぞれのデータの具体例(世帯消費データ,購買履歴)のユースケースを想定した加工アルゴリズム の最適化を試みる.従来は,匿名加工方式とリスク評価の研究はそれぞれ独立にクローズな環境で 行われていたため,多様なリスクを見落とししたり ,偏った視 点での評価になる懸念があった .これに対して,本研究では,オープン型の評価コンテストを行い,多くの研究者による集合知により,公平で信頼できる匿名加工技術の開発を試みる.
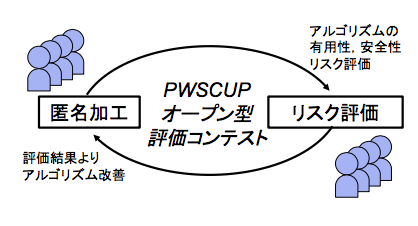
図 2 に本研究のアイデアを示す.ここで,参加者らは匿名加工を行うタスクと加工された匿名加工データを再識別してその安全性を正しく評価するタスクの二つに取り組む.コンテストを通じて,加工の際 に見落としがちなアルゴリズムの脆弱性などの知見を得ることが出来,有用性と安全性のトレードオフ の中で最適と考えられる加工パラメータ (差分プライバシーにおける ε) や評価手法の基準値 (k-匿名性) の値なども,確立することが期待できる.
研究代表者らは,2015 年に情報処理学会コンピュータセキュリティシンポジウムにおいてこのオープン評価コンテスト PWSCUP 2015 を開催した.これは世界で初めてのオープン型の匿名加工コンテストとして知られ,本研究分野に大きな影響を与えた (研究代表者菊池の業績 1, 13, 14, 15). 本コンテストは,購買履歴データを対象として PWSCUP 2016, 2017 にも開催された.2017 年にはプライバシー保護のトップ会議の一つである PETS 2017 にて,国際化に向けたワークショップ Workshop on Design Issues for a data Anonymization Competition (WODIAC) を開催し, 菊池, 中川 (業績 5), 村上 (業績 8) らが発表をしている.機械学習などのコンテストは各種の学術組織で行われているが,匿名加工技術を競う例は他になく,極めて独創的な試みであると言える.
本研究で何をどのように,どこまで明らかにしようとするのか
課題1. 匿名加工技術のオープンデータベース開発
本研究を実施するためには,個人情報としての法的な問題がなく,出来るだけ現実に近い大規模 なデータベースを必要とする.PWSCUP 2016 では UCI Machine Learning Repository にて公開さ れている英国に現存する無店舗型オンラインショッピングサイトにおける 2010 年からの 1 年間の購買履歴の Online Retail Data Set を用いて,購買日,商品,単価,購買数などの 7 種類の属性についての,1 万 8 千レコードを用意した. 本研究では,移動履歴データ, ウェブ閲覧履歴, 健康診断データ,などを候補として表 1 に示す類型をカバーする多様なデータを検討する.
課題2. 有用性指標の設計
匿名加工アルゴリズムの優越を評価するために決めなくてはならない項目として,1. 準識別子 (Quasi Identifier) とみなす静的属性,2. 加工データの有用性指標,3. 再識別リスクを評価する安全性指標がある.これらは,対象とするデータと匿名加工データのユースケースを十分に考慮して決める必要があり,一意には定まらない.準識別子とみなされる属性は,k-匿名性を満たすように加工する対象となるが,その決定にはデータと属性の特性を熟知して行う必要がある.
課題3. 攻撃者の知識モデルと安全性指標
匿名加工データの再識別リスクは,攻撃の際に仮定する背景知識と動機づけなどに大きく依存す る.例えば,PWSCUP 2016 では,サンプル提供した共通の再識別アルゴリズムによる平均再識別 率が 18% ,各チームが互いに試みた平均再識別率が 47 % であり,優勝チームの匿名加工データで も,22%の購買履歴が正しく識別された. このように,最大知識攻撃者モデルでは匿名加工データの 安全性は現実より低く見積もられる傾向があるので,攻撃モデルとして十分ではなく,仮定が強す ぎるとの意見がある.そこで,本課題では,より現実的なモデルとして次の複数のモデルを発展させる.(1) 攻撃者は個人履歴データの一部を知っている部分知識モデル, (2) 多属性索引における統 計攻撃モデル (渡辺業績 35), (3) 履歴のべき乗則に基づいて生起することを仮定した Zipf 分布モデルに基づく履歴データの再識別リスク評価 (菊池業績 12, 情報処理学会論文誌論文賞).
課題4. 多用な匿名化アルゴリズムの開発
(1) 集合値データに対する個人適応型匿名化アルゴリズム. 類似した属性,履歴を持つ個人をクラ スタ化する.そのうえでクラスタ内の履歴データを有用性指標をできるだけ維持しつつランダム化する.この戦略は効果的で,PWSCUP2016 で優勝したチームが採用した.クラスタ化とランダム化 を有機的に組み合わせる手法は本課題を通じて申請者らが独自に発見し開発した匿名化手法である(中川業績 4, ICDM はデータマイニング分野のトップ会議).(2) 局所差分プライバシーに基づく 匿名化アルゴリズム. 加工が過ぎると有用性を失う.そこで,局所差分プライバシーの概念を応用し て,このトレードオフを最適化する必要最低限の加工の幅でデータ主体が独自に摂動化を行う.(佐 久間業績 11 ICML は機械学習トップ会議)
課題5. 欠損位置情報の推定とテンソル分解に基づく個人毎の遷移行列の学習
位置情報を対象とした研究課題である.履歴情報の適切な匿名加工の方法を明確にする.この際, 個人が普段から(SNS などで)公開する移動位置情報は一般には少なく,また一定時間おきに公開 するとも限らないことに注目する.例えば,位置履歴を用いた再識別法として有名なのが,個人毎の 遷移行列を用いた再識別法 [3] であるが,上記のような状況では遷移行列の学習が大きな課題となる.

この課題を解決するため,村上は個人毎の遷移行列を 3 次元テンソルと見なし,(i) 欠損位置情報 の推定と (ii) テンソル分解に基づく遷移行列の学習を繰り返す学習法(図 3 参照)を提案し,上記の ような状況でも高い精度で個人を識別できることを示している(村上の研究業績 7 参照.PoPETs はプライバシー分野のトップ国際誌).
課題 6 PWSCUP の継続的実施による匿名化,再識別の評価環境の構築
以上のような技術課題を申請者のグループだけではなく,この分野に興味を持つ研究者,技術者, データ保有者,データ消費者,情報サービス業者,医療情報研究者,統計学者を結集して客観的に 解決し,その成果を広く一般に周知,発展させるために,匿名化,再識別技術の評価環境を構築する.そのうえで PWSCUP の継続的開催,および国際化を行う.